Elasticsearch Head插件安装、Web页面查询操作与IK分词器配置详解
Elasticsearch作为一款强大的分布式搜索和分析引擎,其丰富的插件生态和便捷的可视化工具极大地提升了开发与运维效率。本文将系统讲解Elasticsearch Head插件的安装部署、Web页面的基本查询操作,以及IK中文分词器的集成与配置,为初学者提供一套完整的基础软件服务实践指南。
一、Head插件安装与部署
Elasticsearch Head是一个用于浏览和与Elasticsearch集群进行交互的Web前端工具。由于Elasticsearch 5.x版本后不再支持直接安装为内置插件,推荐以下两种主流安装方式:
1. 使用Docker快速部署(推荐)
对于追求效率的环境,Docker是最便捷的方式。执行以下命令即可启动一个Head服务容器:
docker run -d -p 9100:9100 mobz/elasticsearch-head:latesthttp://你的服务器IP:9100 即可打开Head管理界面。在界面顶部的连接输入框中,填入你的Elasticsearch服务地址(如 http://localhost:9200)并连接。
2. 从源码运行
如果你希望更深入地定制或了解其原理,可以从GitHub获取源码并运行:
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start重要配置:为了让Head插件能跨域访问Elasticsearch,你需要在Elasticsearch的配置文件 config/elasticsearch.yml 末尾添加以下配置并重启服务:`yaml
http.cors.enabled: true
http.cors.allow-origin: "*"`
二、Web页面查询操作详解
成功连接集群后,Head界面主要包含以下几个功能模块:
- 集群概览:显示集群名称、状态、节点数量、分片统计等健康信息。
- 索引管理:
- 查看所有索引:列出集群中的所有索引及其状态、文档数、存储大小等。
- 新建索引:可以指定索引名称、分片数和副本数进行创建。
- 索引操作:对已有索引执行打开、关闭、删除、清空等操作。
- 数据浏览:选择一个索引后,可以直观地浏览其内的文档数据,以JSON格式展示。
- 复合查询(核心功能):这是最常用的功能区域,允许用户直接编写RESTful API进行查询。
- 查询界面:提供输入框用于指定索引、类型(7.x后逐渐弃用)、查询条件和返回条数。
* 查询语法:支持完整的DSL查询。例如,一个简单的匹配查询:
`json
{
"query": {
"match": {
"title": "Elasticsearch"
}
}
}
`
- 结果展示:查询结果会清晰地显示在下方,包括命中文档的详细内容和元数据(如
<em>score,</em>id)。
- 请求历史:自动保存最近的查询语句,方便调试和复用。
三、IK分词器集成与使用
Elasticsearch默认的分词器对中文支持不友好(按单字拆分),IK分词器是处理中文文本的首选插件。
1. 安装IK分词器
确保安装的IK版本与你的Elasticsearch版本严格匹配。以Elasticsearch 7.x为例:
`bash
# 进入Elasticsearch安装目录的plugins文件夹
cd yourespath/plugins
下载对应版本的IK分词器(以7.17.0为例)
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.0/elasticsearch-analysis-ik-7.17.0.zip
解压到ik目录
unzip elasticsearch-analysis-ik-7.17.0.zip -d ik
删除zip包
rm elasticsearch-analysis-ik-7.17.0.zip`
安装完成后,必须重启Elasticsearch服务。
2. 验证与测试
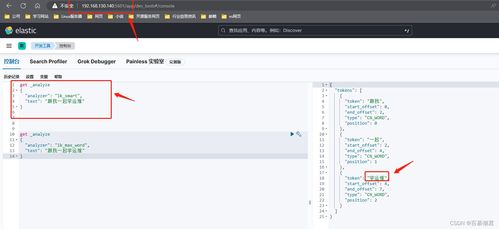
重启后,可以通过Head的“复合查询”界面或curl命令测试IK分词器是否生效。
* 测试iksmart(最粗粒度拆分):
`json
POST analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
`
结果可能为:[中华人民共和国, 国歌]
* 测试ikmaxword(最细粒度拆分):
`json
POST analyze
{
"analyzer": "ikmax_word",
"text": "中华人民共和国国歌"
}
`
结果可能为:[中华人民共和国, 中华人民, 中华, 华人, 人民共和国, 人民, 共和国, 共和, 国歌]
3. 在索引映射中应用IK分词器
创建索引时,在映射中指定字段使用IK分词器:
PUT /my_index
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ikmaxword", // 写入时采用细粒度分词
"searchanalyzer": "iksmart" // 查询时采用粗粒度分词,提高召回率
}
}
}
}4. 扩展自定义词典
IK分词器支持自定义词汇,以提升分词准确性。编辑 plugins/ik/config/IKAnalyzer.cfg.xml 文件,可以指定扩展词典和停用词典的路径,将你的专业词汇添加到 ext.dic 文件中即可。修改后需重启ES或对特定索引调用 _reload API生效。
###
通过安装Head插件,我们获得了管理Elasticsearch集群和进行数据查询的图形化利器。结合功能强大的IK中文分词器,我们可以构建出更贴合中文语境的搜索与分析应用。这三者构成了Elasticsearch基础软件服务中不可或缺的环节,熟练掌握它们将为后续构建复杂的搜索和数据分析功能奠定坚实基础。在实践中,建议多利用Head的查询界面进行DSL语句的练习和调试,并依据业务需求不断优化IK分词器的词典配置。
如若转载,请注明出处:http://www.o2ocaishen.com/product/56.html
更新时间:2026-06-18 22:58:42